Artificial
Intelligence 3E
foundations of computational agents
3.2 State Spaces
One general formulation of intelligent action is in terms of a state space. A state contains all of the information necessary to predict the effects of an action and to determine whether a state satisfies the goal. State-space searching assumes:
-
•
The agent has perfect knowledge of the state space.
-
•
At any time, it knows what state it is in; the world is thus fully observable.
-
•
The agent has a set of actions with known deterministic effects.
-
•
The agent has a goal to achieve and can determine whether a state satisfies the goal.
A solution to a search problem is a sequence of actions that will get the agent from its current state to a state that satisfies the goal.
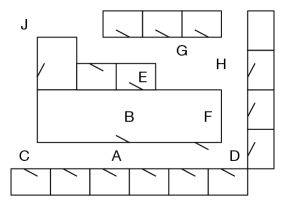
Example 3.2.
Consider the robot delivery domain of Figure 3.1, where there are offices around a central lab. The only way a robot can get through a doorway is to push the door open in the direction shown. The task is to find a path from one location to another. Assuming that the agent can use a lower-level controller to get from one location to a neighboring location, the actions for the search are traveling between neighboring locations. This can be modeled as a state-space search problem, where the states are locations. Some of the locations in Figure 3.1 are named and used as exemplars.
Consider an example problem where the robot starts at location , and the goal is to get to location . Thus, is the only state that satisfies the goal. A solution is a sequence of actions that moves the robot from to .
Example 3.3.
Consider a video game played on a grid, where an agent can move up, down, left, or right one step as long as the move is not blocked by a wall. The agent has to collect four coins, , where each coin starts at a known position. The agent uses one unit of fuel at each step, and cannot move if it has no fuel. It can get filled up (to 20 units of fuel) at the fuel station. In this case the state needs to take into account the position of the agent, the amount of fuel, and for each coin whether it has collected that coin. The state could be represented as the tuple
where is the position of the agent, is the amount of fuel the agent has, and is true when the agent has collected coin . True is written as and false as here. The goal might be for the agent to have collected all coins and be at position , which is the state
where ? means what the fuel is at the end does not matter. All states where the agent is at and all are true are goal states.
Part of the environment is shown in Figure 3.2(a), where the agent cannot move into a blacked-out square. It could get filled up at position and collect coin at position .
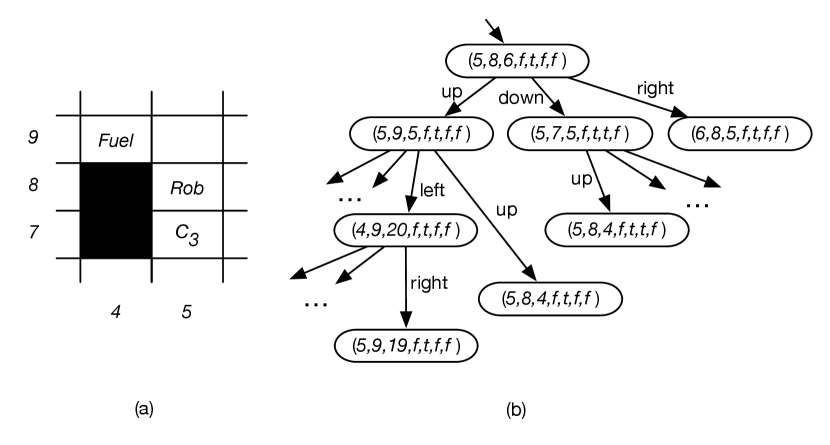
The state where the agent, Rob, is at position with 6 units of fuel, and has only collected coin , is
Figure 3.2(b) shows part of the state space for this problem.
Example 3.4.
The delivery robot may have a number of parcels to deliver to various locations, where each parcel has its own delivery destination. In this case, the state may consist of the location of the robot, which parcels the robot is carrying, and the locations of the other parcels. The possible actions may be for the robot to move, to pick up parcels that are at the same location as the robot, or to put down some or all of the parcels it is carrying. A goal state may be one in which some specified parcels are at their delivery destination. There may be many goal states because where the robot is or where some of the other parcels are in a goal state does not matter.
Notice that this representation has ignored many details, for example, how the robot is carrying the parcels (which may affect whether it can carry other parcels), the battery level of the robot, whether the parcels are fragile or damaged, and the color of the floor. Not having these details as part of the state space implies that they are not relevant to the problem at hand.
Example 3.5.
In a simplified tutoring agent, a state may consist of the set of topics that the student knows, and the topics they have been introduced to, but do not know yet. The action may be teaching a lesson on a particular topic, with preconditions that the student knows any prerequisite topic, and the result that the student knows the topic of the lesson. The aim is for a student to know a particular set of topics.
If the effect of teaching also depends on the aptitude of the student, this detail must be part of the state space as well. The state does not need to include the items the student is carrying if what they are carrying does not affect the result of actions or whether the goal is achieved.
A state-space search problem consists of:
-
•
a set of states
-
•
a distinguished state called the start state
-
•
for each state, a set of actions available to the agent in that state
-
•
an action function that, given a state and an action, returns a new state
-
•
a goal specified as a Boolean function, , that is true when state satisfies the goal, in which case is a goal state
-
•
a criterion that specifies the quality of an acceptable solution; for example, any sequence of actions that gets the agent to the goal state may be acceptable, or there may be costs associated with actions and the agent may be required to find a sequence that has minimal total cost.
A solution that is best according to some criterion is called an optimal solution. An agent may be satisfied with any solution that is within, say, 10% of optimal.
This framework is extended in subsequent chapters to include cases where the states have structure that can be exploited, where the state is not fully observable (e.g., the robot does not know where the parcels are initially, or the teacher does not know the aptitude of the student), where the actions are stochastic (e.g., the robot may overshoot, or a student perhaps does not learn a topic that is taught), and with complex preferences in terms of rewards and punishments, not just a set of goal states.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.