Artificial
Intelligence 3E
foundations of computational agents
3.4 A Generic Searching Algorithm
This section describes a generic algorithm to search for a solution path in a graph. The algorithm calls procedures that can be coded to implement various search strategies.
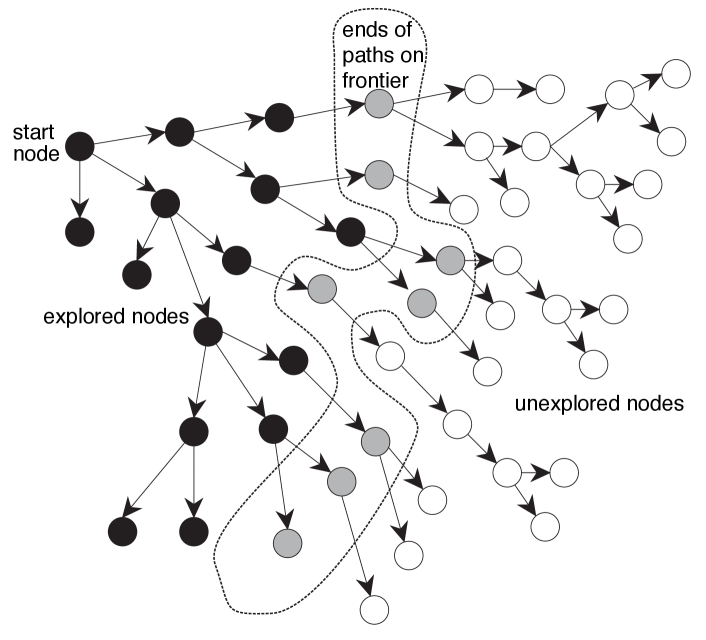
The intuitive idea behind the generic search algorithm, given a graph, a start node, and a goal predicate, is to explore paths incrementally from the start node. This is done by maintaining a frontier (or fringe) of paths from the start node. The frontier contains all of the paths that could form initial segments of paths from the start node to a goal node. (See Figure 3.4, where the frontier is the set of paths to the gray-shaded nodes.) Initially, the frontier contains the trivial path containing just the start node, and no arcs. As the search proceeds, the frontier expands into the unexplored nodes until a goal node is encountered. Different search strategies are obtained by providing an appropriate implementation of the frontier.
The generic search algorithm is shown in Figure 3.5. The frontier is a set of paths. Initially, the frontier contains the path of zero cost consisting of just the start node. At each step, the algorithm removes a path from the frontier. If is true (i.e., is a goal node), it has found a solution and returns the path . Otherwise, the path is extended by one more arc by finding the neighbors of . For every neighbor of , the path is added to the frontier. This step is known as expanding the path .
This algorithm has a few features that should be noted:
-
•
Which path is selected at line 13 defines the search strategy. The selection of a path can affect the efficiency; see the box for more details on the use of “select”.
-
•
It is useful to think of the return at line 15 as a temporary return, where a caller can retry the search to get another answer by continuing the while loop. In languages that support object-oriented programming, such as Python, retry can be implemented by having a class that keeps the state of the search and a method that returns the next solution.
-
•
If the procedure returns (“bottom”), there are no solutions, or no remaining solutions if the search has been retried.
-
•
The algorithm only tests if a path ends in a goal node after the path has been selected from the frontier, not when it is added to the frontier. There are two important reasons for this. There could be a costly arc from a node on the frontier to a goal node. The search should not always return the path with this arc, because a lower-cost solution may exist. This is crucial when the lowest-cost path is required. A second reason is that it may be expensive to determine whether a node is a goal node, and so this should be delayed in case the computation is not necessary.
Non-deterministic Choice
In many AI programs, we want to separate the definition of a solution from how it is computed. Usually, the algorithms are non-deterministic, which means that there are choices in the program that are left unspecified. There are two forms of non-determinism:
-
•
In don’t-care non-determinism, if one selection does not lead to a solution, neither will other selections. Don’t-care non-determinism is used in resource allocation, where a number of requests occur for a limited number of resources, and a scheduling algorithm has to select who gets which resource at each time. Correctness should not be affected by the selection, but efficiency and termination may be. When there is an infinite sequence of selections, a selection mechanism is fair if a request that is repeatedly available to be selected will eventually be selected. The problem of an element being repeatedly not selected is called starvation. In this context, a heuristic is a rule-of-thumb that can be used to select a value.
-
•
In don’t-know non-determinism, just because one choice did not lead to a solution does not mean that other choices will not. It is useful to think of an oracle that could specify, at each point, which choice will lead to a solution.
Don’t-know non-determinism plays a large role in computational complexity theory. A decision problem is a problem with a yes or no answer. The class consists of decision problems solvable in time complexity polynomial in the size of the problem. The class , of non-deterministic polynomial time problems, contains decision problems that could be solved in polynomial time with an oracle that chooses the correct value at each choice in constant time or, equivalently, if a solution is verifiable in polynomial time. It is widely conjectured that , which would mean that no such oracle can exist. One pivotal result of complexity theory is that the hardest problems in the class are all equally complex; if one can be solved in polynomial time, they all can. These problems are NP-complete. A problem is NP-hard if it is at least as hard as an NP-complete problem.
In a non-deterministic procedure, pretend that an oracle makes an appropriate choice at each time. A choose statement will result in a choice that will lead to success, or will fail if there are no such choices. A non-deterministic procedure may have multiple answers, where there are multiple choices that succeed, and will fail if there are no applicable choices. An explicit fail in the code indicates a choice that should not succeed. Because our agent does not have an oracle, it has to search through the space of alternate choices.
This book consistently uses the term select for don’t-care non-determinism and choose for don’t-know non-determinism.
Artificial Intelligence: Foundations of Computational Agents, Poole
& Mackworth
Copyright © 2023, David L. Poole and Alan K. Mackworth. 
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.